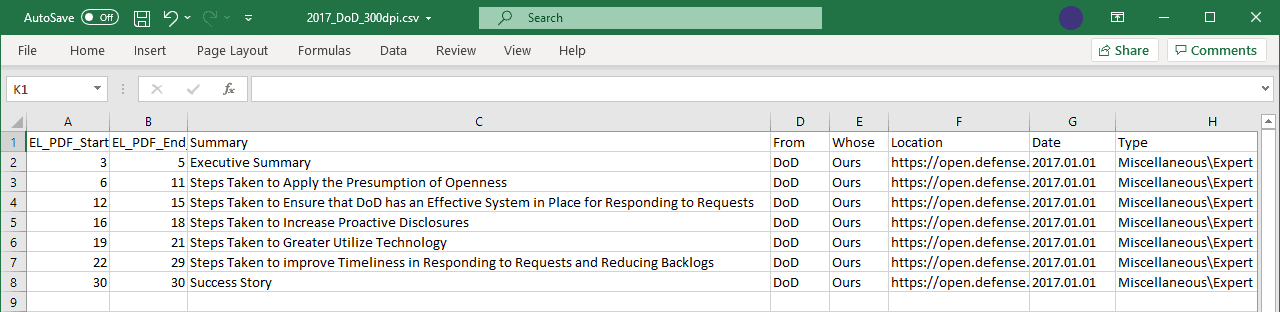
Almost any PDF viewer like Adobe Acrobat DC, Adobe Acrobat Pro for Mac, Foxit, etc. (excluding readers like Adobe Acrobat Reader DC) will let you split a PDF manually. A PDF cutter helps automate part of that, but a law firm needs to classify, organize, review, and analyze the key information in each split pdf. Bulk rename is hardly of any value at all: each filename and date prefix will be different, as will the document’s author, recipient, description, etc. Whether a response to an FOIA request or a medical record, that means reviewing, renaming, and organizing each individual PDF file, manually. Make sure to have significant amounts of time on hand!
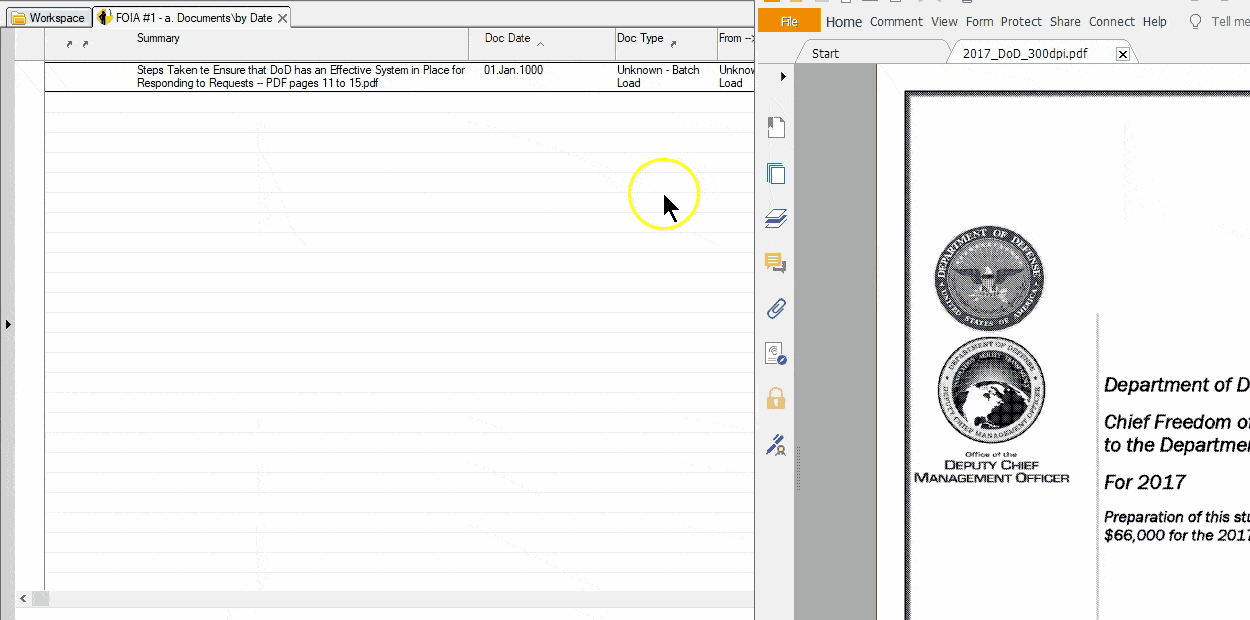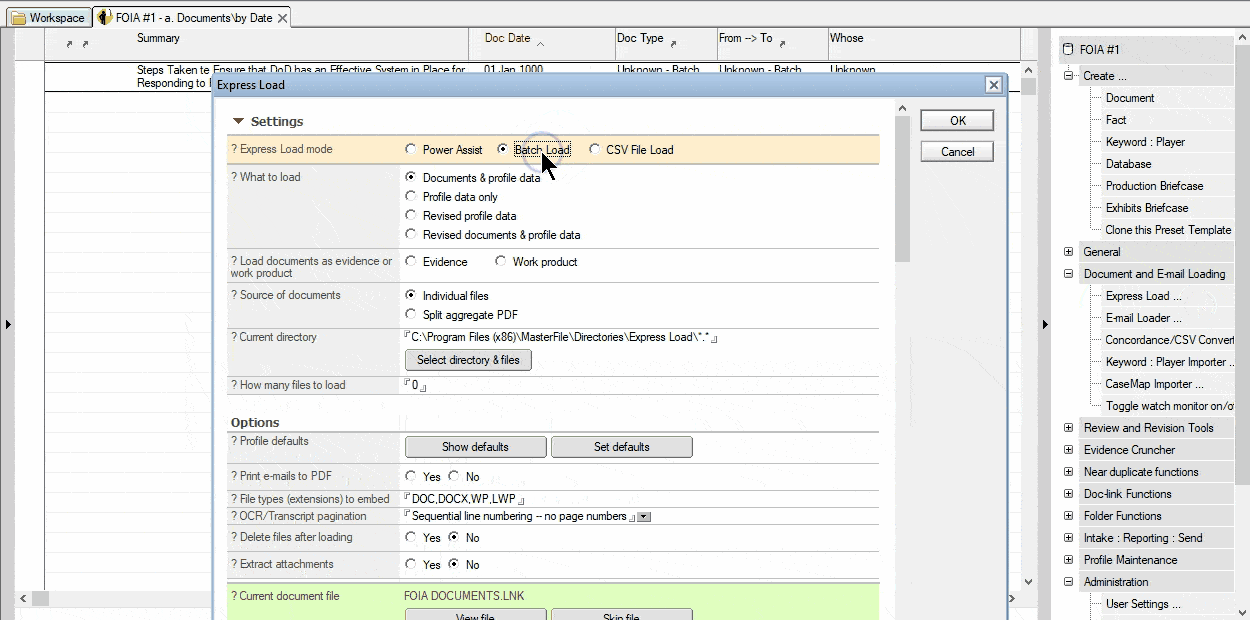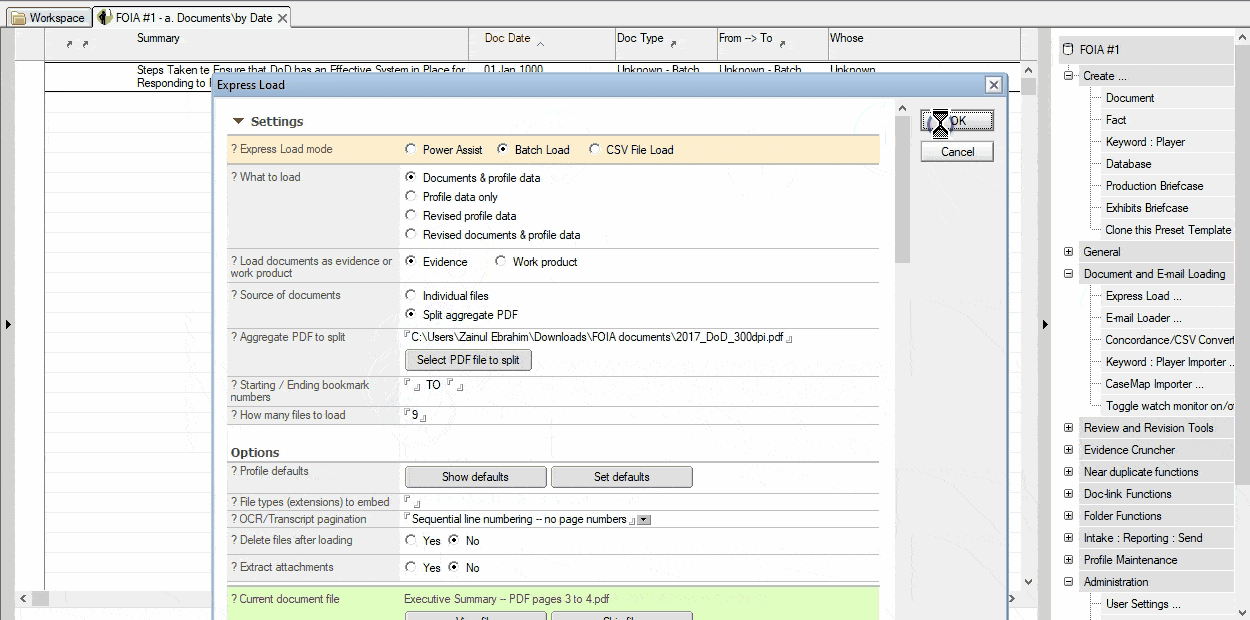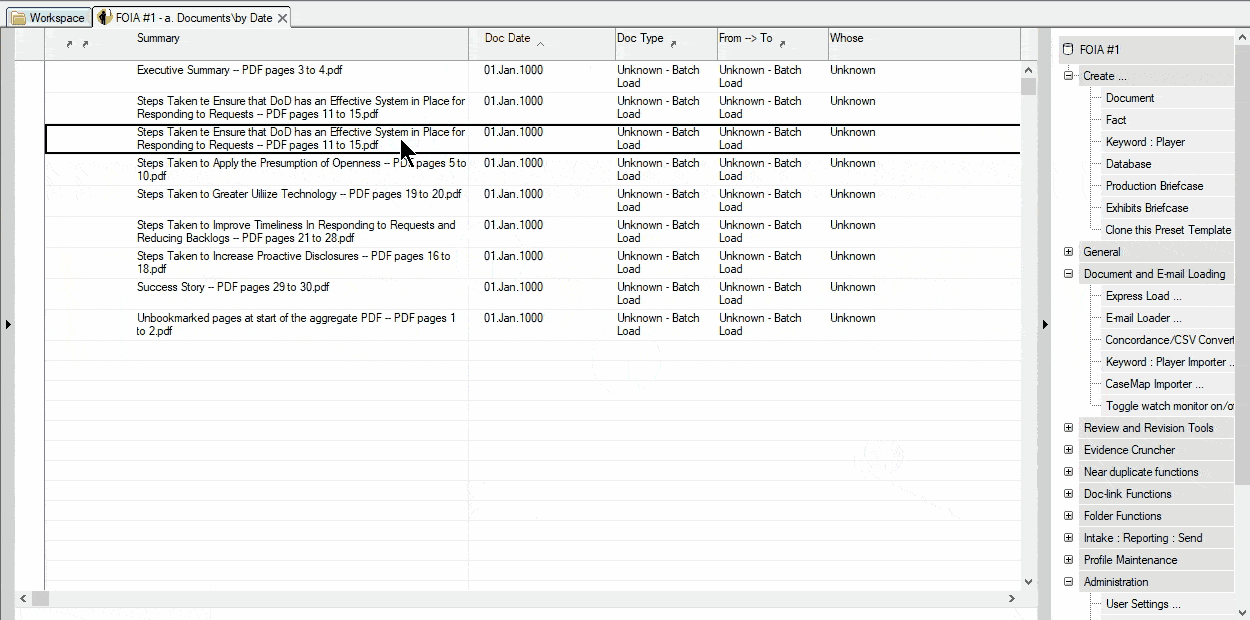
MasterFile automates this document-splitting process for you. A multi-page PDF file will be split directly into logical documents as it is loaded; no additional software is needed. Whether you split a PDF using its dozens of bookmarks, or via a mapping using Excel, file organization takes place automatically. Content on one PDF page belonging to consecutive documents is also managed correctly. As new single or multi-page PDFs are created, review, mark key extracts, classify by legal issue, add notes and metadata, etc. Or, use MasterFile’s bulk loading and batch processing features and defer review to later.
Other PDF related advanced features include creating briefs, exhibit and witness profiles, and disclosure sets in PDF hyperlinked to underlying evidentiary documents, and more.
MasterFile is more than a PDF tool. It’s the perfect tool for litigation, case management and case analysis for your firm on both Windows and Mac operating systems.